Hash index
Just like B-tree index, we also have a concept of a hash index.
- A hash index is built on a hash table.
- It increases performance for exact lookups. The logic behind hash index is very simple.
For each row, a hash code is generated. Generally, different keys generate different hash codes. It stores hash code in index with pointers to each row in a hash table. If there are multiple values with the same hash code, it will also contain the row pointers in a linked list. It looks like hash index has very similar logic as hash algorithm, and that's true. If from this bullet point it's not clear to you how hash indexes work, we will see that with the help of visualization. Here is one more thing to remember, memory storage engines in MySQL supports explicit hash tables. Hash indexes are very fast and effective as it resides in memory. Let's quickly look at limitations of hash indexes before we jump to visualization.
Limitations of hash index
Hash indexes are lightning fast, however, there are few limitations associated with it.
The reason for limitation is it only contains hash code and row pointers and not real data in the index.
- As hash codes do not contain original data, it is not effective in:
- sorting and
- partial matching
The example of partial matching queries would be to find all the first names starting with the letter A.
- Hash index only supports equal to operator. If you have any other operator in your query, hash indexes will not be effective or useful.
- Multiple values with the same hash code, it will result in slower performance. Generally, a different case generates different hash codes, but due to any reason, if your table is very huge, it's quite possible to have multiple rows with the same hash code.
- This is because the storage engine will follow each row pointer in the linked list and compare the value to the lookup values to get necessary data.
- Slow maintenance
Well, from this limitation, it's very clear that hash code is not the answer to all the questions. In InnoDB, we have a concept called adaptive hash index, which closely works with B-tree index. Let's understand what adaptive hash index is.
Adaptive hash index
- InnoDB storage engine supports adaptive hash index.
- This is an automatic process. It does not give us any control to configure it.
- Definitely we can disable adaptive hash index, but we cannot do any modification in this algorithm.
- Definitely we can disable adaptive hash index, but we cannot do any modification in this algorithm.
- Hash indexes are built in memory on the top of frequently used B-tree indexes.
MySQL engine automatically figures out which are the most frequently used B-tree indexes. It will take those B-tree indexes and values and put them into memory. In the memory, it will build hash index on the top of it. Now, your storage engine has definitely B-tree indexes and on the top of it there are hash indexes in memory.
When MySQL engine receives any query, it will evaluate it for hash index, as well as B-tree indexes. - If there are scan or any other situation where we have used different operators than equal to, it will directly use B-tree indexes.
- However, there is a direct lookup of any particular value, MySQL engine will use in memory hash index to get data immediately.
In other words, adaptive hash index gives B-tree indexes very fast hash lookups for improved performance.
This is one of the reasons why InnoDB storage engine is getting more popular into various installations of MySQL and more and more people are migrating from MyISAM to InnoDB for performance.
If your storage engine does not support hash indexes, you can also simulate them yourself manually. However, this process is very complicated and maintenance of those hash indexes can be a nightmare sometimes.
Building Hash Index
Let's understand how hash index works visually.
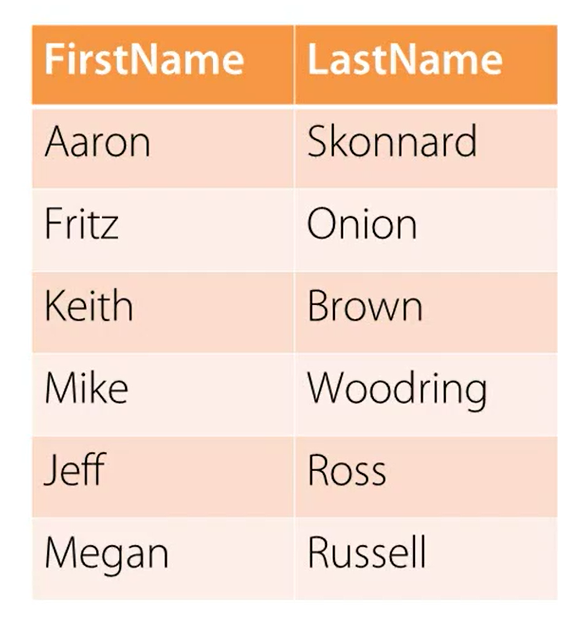
Let's assume that we have a single table, it has six rows, Aaron, Fritz, Keith, Mike, Jeff, and Megan.
Let's assume that our query is on FirstName. For example, our query is:
select FirstName, LastName from TableName where FirstName is equal to Jeff. That means we're going to look up for FirstName is equal to Jeff in the FirstName column.
Let's build our hash index on our FirstName column.
We applied a random hash function on our FirstName column and here is our result. 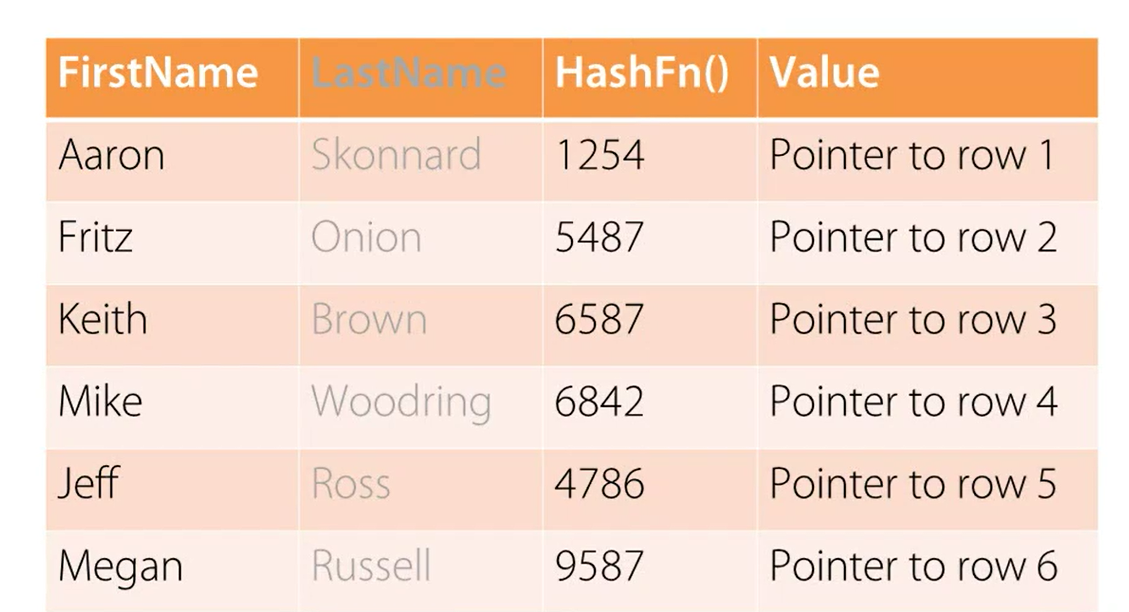
The hash function generates a different value for each row in our table.
The first two columns, FirstName and LastName are the original table.
Function name and Value are columns from our hash index. Column value will contain a pointer to the row on which hash function is applied. In our case, we are looking for Jeff Ross as an answer to our query.
Now, let's understand how a query works internally.

On the left side, we have a hash index and on the right side we have the original table.
Here is our query. Select FirstName, LastName from TableName where FirstName is equal to Jeff.
First, function is applied on value Jeff. It will return as value 4786.
Now, the same query is internally rewritten as SELECT Value from TableName where hash function is equal to 4786. That will return us this result.
4786 value is located in our hash index. It will also point us to row #5. MySQL engine will look up internally row #5 and will give us value Jeff Ross as our final result.
When you understand how a hash index works, you can see that hash index logic is very simple.
It is very efficient and it improves the performance of the query massively.
However, please note that I have just created this example for our understanding. The hash function value, which I've generated, is a representation of what MySQL engine might have originally generated. As I mentioned earlier, in InnoDB storage engine, hash index is an automatic process and there is no control or configuration possible. Hash indexes are automatically built in memory on the top of frequently used B-tree indexes.
If you're using InnoDB as your storage engine for performance you need to focus only on building right B-tree indexes.