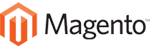Clustered index - keypoints
- Clustered index is just a different approach of data storage. This is not a different type of index, and not all the engines support it.
- Rows with adjacent key values are stored close to each other.
- It is possible to have only one cluster index per table, but you can use different keys and build a secondary index
Advantages of clustered index:
- Related data is stored close to eachother leading to less disk I/O while retrieving sequential or range data
- Faster data access as data and index are stored together at leaf node and leaf node are pointing to each other using pointers -Performance
Disadvantages of clustered index:
- Data insertion speed is dependent on the order of Primary Key when there is a clustered index on the table
- Table needs to be optimized if inserted data is not ordered by Primary Key
- Clustered index have minimal impact for in memory data
- Updating the clustered index column is expensive (resource wise) as data is moved based on its size to different location
- Page split occurs when new data is inserted leading to fragmentation
- Alot of fragmentation will lead to bad performance of entire server
- Secondary index (non cluster index) does not store actual data, but it contains the location of the clustered index instead of raw pointer, hence the size is larger
- if there is a clustered index, secondary index will contain the pointer to the clustered index
- if there is no clustered index, secondary index will contain the row pointer to the actual data
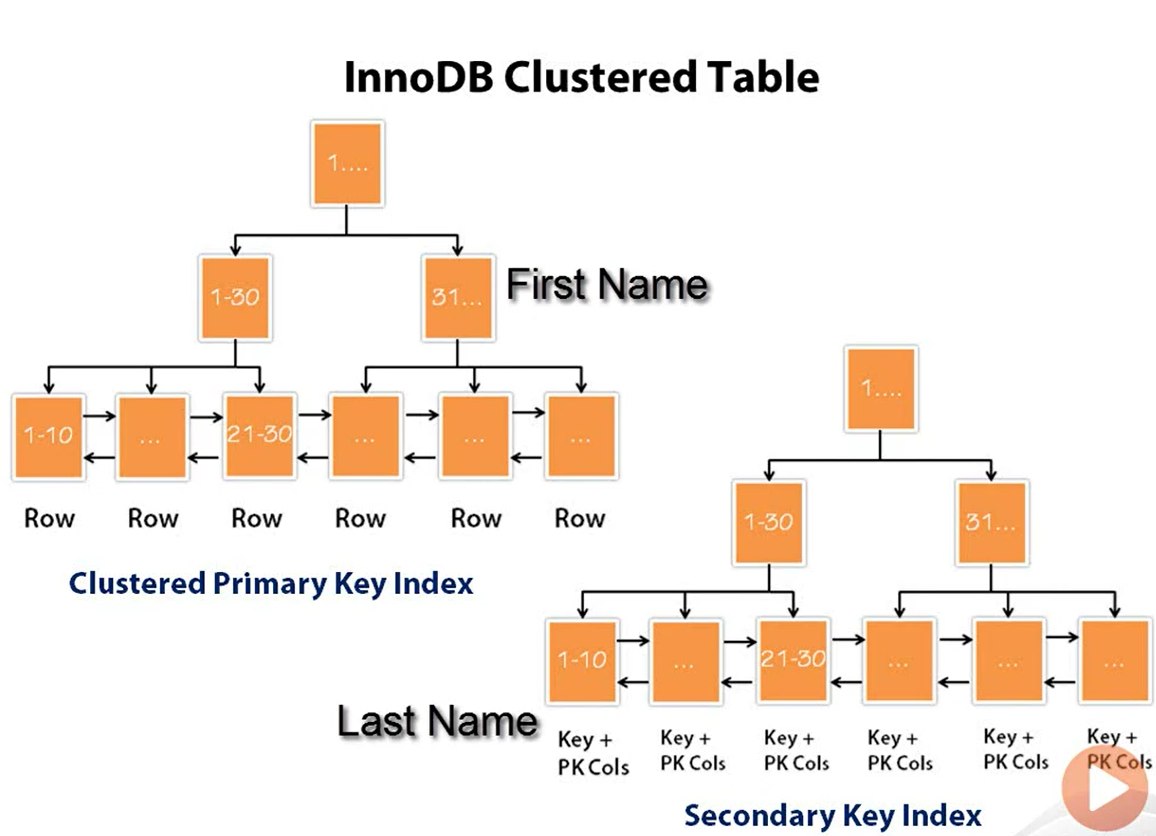
In clustered innodb we only have data in leaf node. Root and Intermediate Node will only contain a pointer to the next level node.
Let's say we want to retrieve Raw 22, mysql engine will traverse from Root node, to intermediate node and end up to Leaf Node.
If we want to retrieve values between raw 22 and 32, then it will use a forward pointer to retrieve the data from the neighbor leaf. This saves alot of I/O.
It will first ask the Root node where this value resides at, Root node will send to intermediate node 1-30 which contains location of raw 1-30 -> then to leaf node
Leaf node will contain entire data ordered by key column
Secondary Index for Innodb
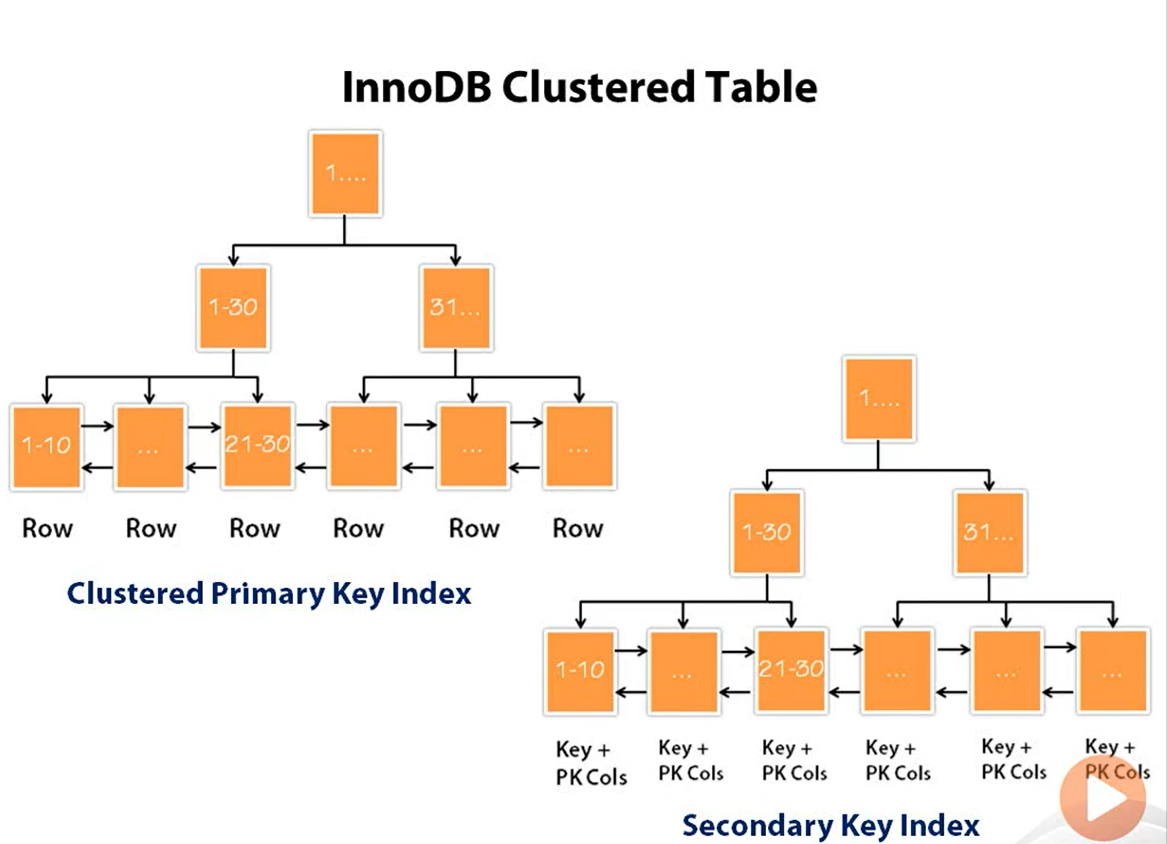
So the question we have, why is there a need to use a secondary index?
The answer is that in practice it is not possible always to honor our cluster index as per all our queries. If the first query is for the first name and the second query is for the last name we clearly need different index.
So if we use the primary index for the first name we can use the secondary index for the last name.